High Level Languages enhance programmer productivity and code readability. However, the ease of use of these languages comes at a performance cost. As Moore’s Law ends, CPU performance increases cannot meet the growing demands of programs using high level languages. Serialization and marshaling are necessary to transfer high level objects over the network. During serialization, objects are transformed from their original format in the native language to a byte array, which is network friendly. This process was originally a relatively small performance cost because of high network latencies. However, as network latencies decreased with the wide adoption of Remote Direct Memory Access (RDMA), serialization became the largest cost of distributed applications that use high level languages. We propose a hardware accelerator that quickly turns non-contiguous, high level objects into byte arrays, greatly reducing the cost of object serialization. This turns a process that requires several microseconds into one that requires only tens of cycles.
Motivation
JAVA and other high level languages are popular because they are easy to learn and use. While JIT compilers improved performance greatly compared to lower-level languages such as C/C++, Java still falls short in several areas. For example, in distributed computing, Java objects are not compatible with the network and must be converted into a byte array before being used in I/O operations. The process of converting an object into a byte array is called serialization. Originally serialization was a negligible cost compared to the high latencies of the network. However, because of the wide adoption of RDMA in data-centers, network latencies have dropped several orders of magnitude and are now often <1us. Several common distributed applications, such as key-value stores and analytics frameworks are now bottlenecked by CPU performance, not by the network, largely due to serialization costs.
System Design
The accelerator is designed to be incorporated on-chip with the CPU. The accelerator would then share an address space and caches with the CPU. How to share the accelerator between various processes each with their own address space is left for future work. While it was designed to be an SoC, we were unable to implement it as one due to time constraints and is instead implemented as an FPGA. All code was written in Chisel and compiled into Verilog.
Our accelerator has two phases, setup and serialize. After the ”Setup Done” instruction is received, the accelerator moves from the setup phase to the serialize phase. During the setup phase, each class that extends serializable is uploaded to the accelerator. The accelerator replies to each class with a class ID, which is used later by the application to notify the accelerator which class needs to be serialized. Once all classes have been uploaded and stored on the accelerator, the application notifies the accelerator that the setup phase is finished. The application starts running normally, and the accelerator waits for instructions from the application. When the application needs to serialize an object, it sends the class ID to the accelerator, which looks up the type and ID values for the class. The application then begins sending the address for each field to the accelerator. If the type is variable length, the length of the field is also sent from the host to the accelerator. The accelerator then reads the data from memory and writes the serialized format to an output buffer. If the CPU passes in the address 0, then the accelerator knows that field is not being used, and can be omitted from the serialized buffer. After the entire object is serialized, the accelerator replies with a notification that the object was serialized.
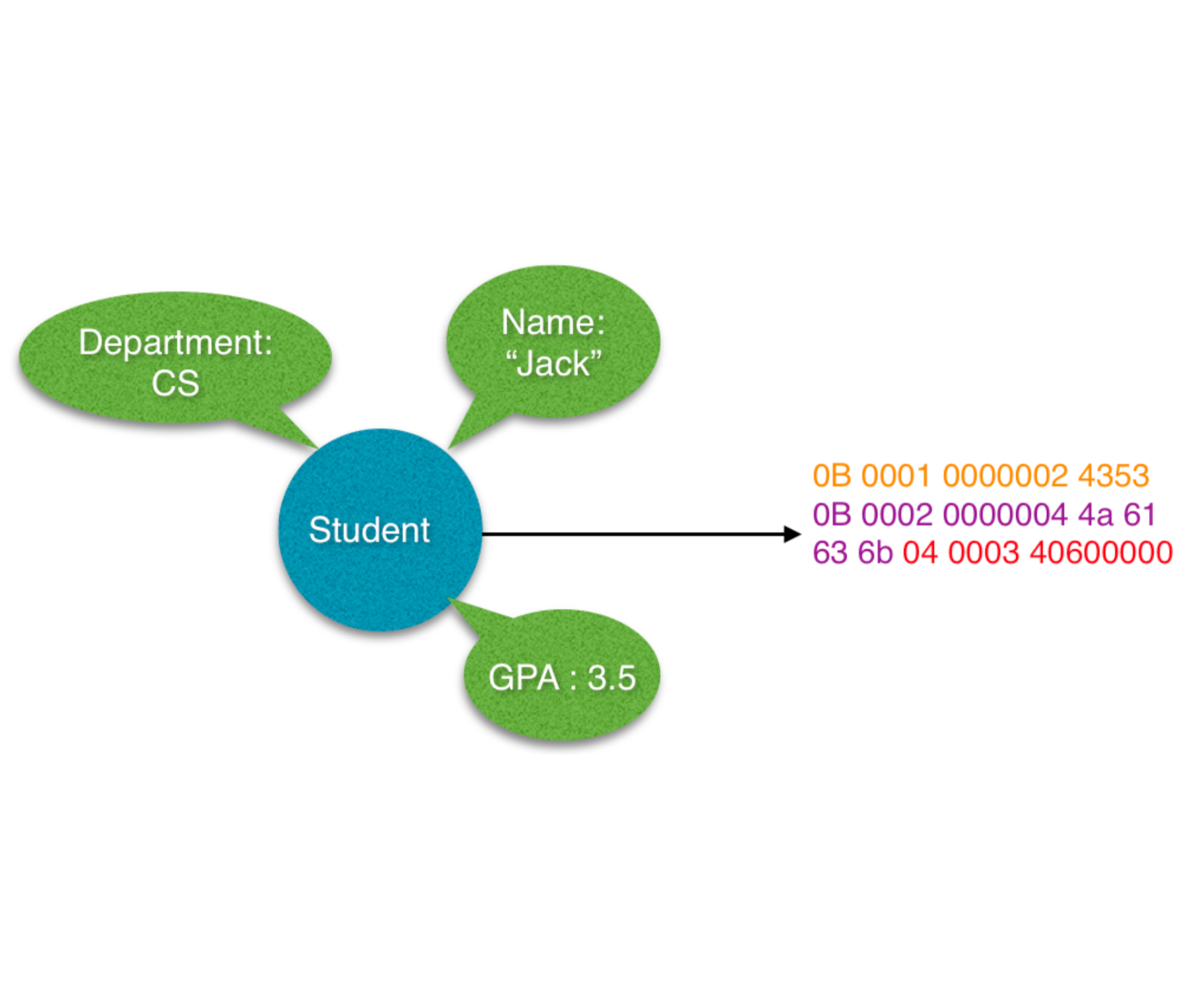
The accelerator is design around the observation that a class looks exactly the same each time it is serialized except for changes between the values of fields. We store the common aspect between objects of the same class in fast on-chip memory, which can be concatenated with the value of the field and written to the output buffer, which would also be on chip. To implement this, we have three arrays stored in the on-chip memory: the Class Table, Type Table, and ID Table. Each index in the Class Table corresponds to a class that the host setup to be serialized. In Figure 3, the host setup 4 classes to be serialized. The Class Table is indexed using the Class ID that is assigned during the setup phase and passed in for each object during the serialize phase. The data stored in the Class Table corresponds to where the fields for that class lie in the Type and ID tables. Each of the entries in the Type Table is 8 bits, and each entry in the ID Table is 16 bits. The size of an entry comes from Thrift, which uses an 8 bit unsigned integer to represent the type of a field, and a 16 bit unsigned integer to represent the ID of the field.
Evaluation
Java serialization is the process of turning an object into a byte array, which can be used for I/O. This involves marshaling the data and adding context to the data, so it can be recreated once received by another server in the system. There are numerous serialization protocols. The benchmark we used included 18 different serializers [6]. We model ours after the Thrift serialization protocol included in the Thrift RPC API, which was developed by Facebook.
Results were collected using the VCS simulator and deploy- ment on an Amazon F1 instance. For the simulation results, we report cycles taken to serialize and compare it with the cycles taken using the thrift serialization protocol. For F1 results, we report wall clock time and compare it with the time taken to serialize in Thrift. All software benchmarking was done on a Duke VM with a Intel Xeon Gold 6140 CPU with a 2.3 GHz clock rate. The object being serialized for both hardware and software has 2 integers and 1 string. The software benchmark had a more complicated object, but only the time taken to serialize a portion with 1 string and 2 integers was measured. The object was serialized 100 times, and the average was taken as the result. All fields are assumed to be close to memory. For the hardware, this means storing the data in on-chip memory, and in the software version is achieved with a warmup phase, so the data being serialized is in the cache.
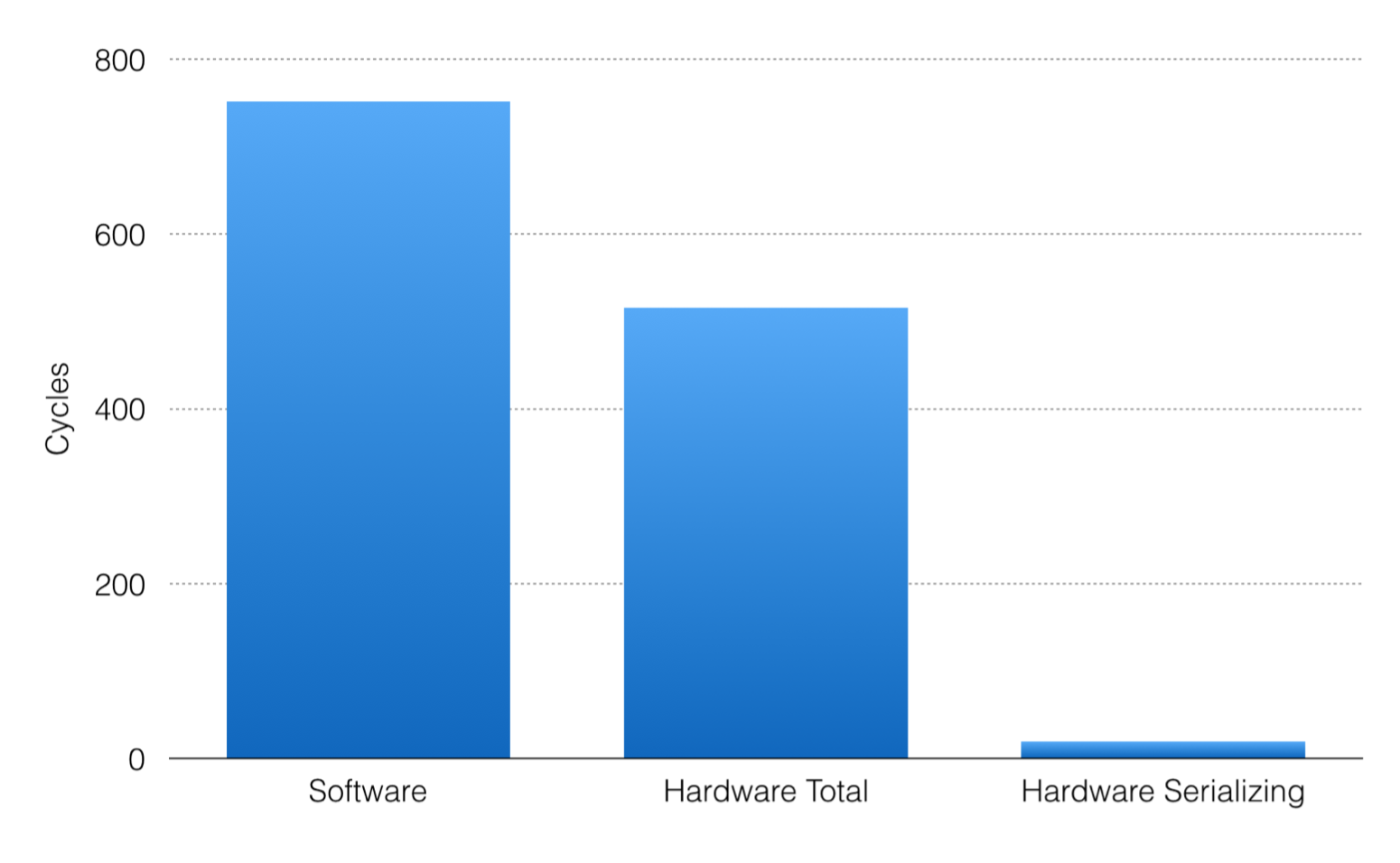
Figure above shows the results of the VCS simulations. The software version takes 750 cycles to serialize the object, while the hardware version takes only 516 cycles, including the latency of waiting for instructions. This is only a 1.5x speedup. However, if we remove the cycles spent waiting for more instructions to arrive from the CPU, the number of cycles taken drops to only 19, resulting in a 39x speedup. While assuming no latency for communication between a CPU and an accelerator is unrealistic, this shows a our accelerator would benefit greatly from a more tight integration with the CPU.
Our deployed accelerator, however, performs very poorly compared to the software implementation due to the loose integration of an FPGA with a CPU and the much lower clock frequency of the FPGA (125 Mhz) compared to the CPU (2.3 Ghz). With the improvements such as pipelined parallelism, a higher clock frequency, and a tighter integration with the CPU, the deployed accelerator will serialize much faster than software.
Conclusion
We showed the feasibility and architecture of an accelerator for Java serialization. While we did not achieve the performance we wanted at deployment, we explained how this was due to the environment that it was designed and deployed in, and performance should be improved when it is incorporated into an SoC.